Day 43 - S3 Programmatic access with AWS-CLI

Cloud Storage
What is Cloud Storage?
Cloud storage is a web service where your data can be stored, accessed, and quickly backed up by users on the internet. It is more reliable, scalable, and secure than traditional on-premises storage systems.
Cloud storage is offered in two models:
Pay only for what you use
Pay on a monthly basis
Types of Cloud Storage
AWS offers the following services for storage purposes:
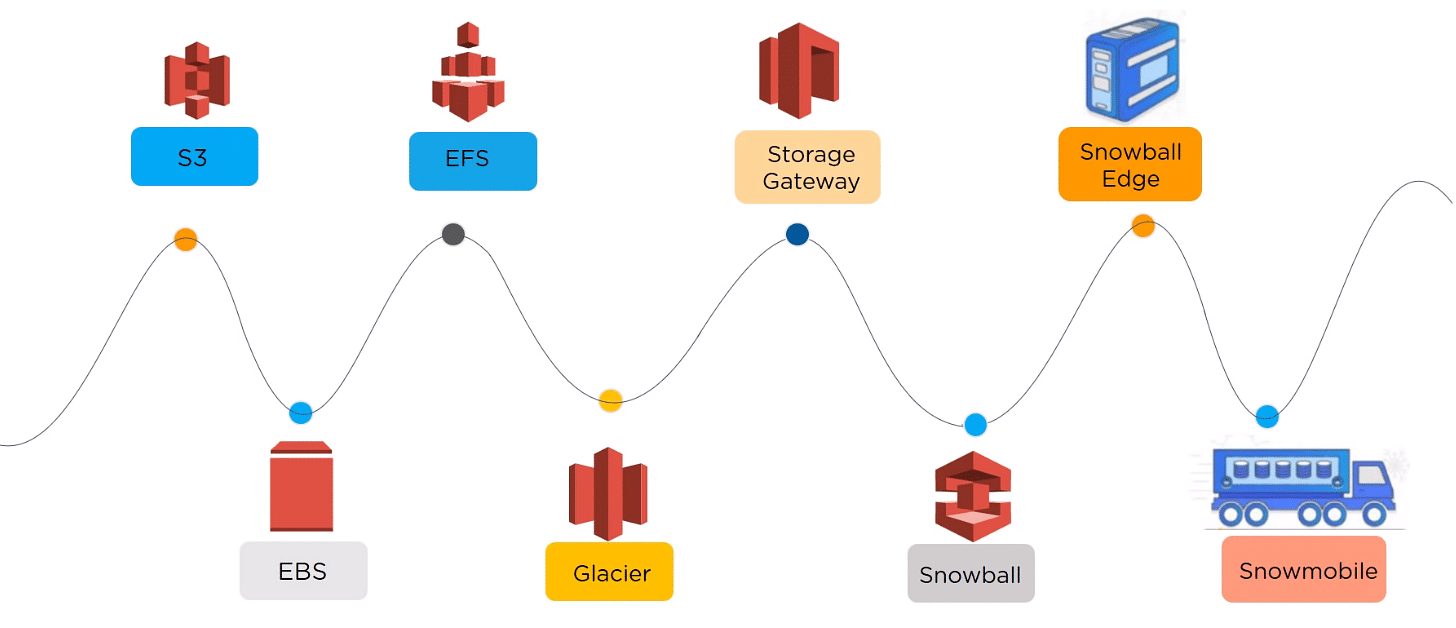
We’ll eventually take an in-depth look at the S3 service. But before we get to that, let’s have a look at how things were before we had the option of using Amazon S3.
Before Amazon S3
Organizations had a difficult time finding, storing, and managing all of your data. Not only that, running applications, delivering content to customers, hosting high traffic websites, or backing up emails and other files required a lot of storage. Maintaining the organization’s repository was also expensive and time-consuming for several reasons.
Challenges included the following: -
Having to purchase hardware and software components
Requiring a team of experts for maintenance
A lack of scalability based on your requirements
Data security requirements
Amazon Simple Storage Service(Amazon S3)

What is Amazon S3?
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere.
Amazon S3 lets you manage your data via the Amazon Console and the S3 API.
Amazon S3 automatically creates multiple data replicas, so it is never lost.
Benefits of using Amazon S3
Some of the benefits of AWS S3 are:
Object Storage: S3 is an object storage service, which means it stores data as objects rather than as files in a hierarchical file system. Each object consists of data, a unique key (or identifier), and metadata.Durability: S3 provides 99.999999999 percent durability.Low cost: S3 lets you store data in a range of “storage classes.” These classes are based on the frequency and immediacy you require in accessing files.Scalability: S3 charges you only for what resources you actually use, and there are no hidden fees or overage charges. You can scale your storage resources to easily meet your organization’s ever-changing demands.Availability: S3 offers 99.99 percent availability of objectsSecurity: S3 offers an impressive range of access management tools and encryption features that provide top-notch security.Flexibility: S3 is ideal for a wide range of uses like data storage, data backup, software delivery, data archiving, disaster recovery, website hosting, mobile applications, IoT devices, and much more.Simple data transfer: You don’t have to be an IT genius to execute data transfers on S3. The service revolves around simplicity and ease of use.Versioning: S3 supports versioning, allowing you to preserve, retrieve, and restore every version of every object stored in a bucket. This is useful for data protection and compliance.
Amazon S3 Use Cases
Some of the use cases of Amazon S3 include: -
Static Website Hosting: Amazon S3 helps in hosting static websites. Hence users can use their domain. Serverless Web Applications can be developed using S3 and by using generated URLs, users can access the application.Backup & Recovery: Amazon S3 helps create backups and archive critical data by supporting Cross Region Replication. Due to versioning, which stores multiple versions of each file, it is easy to recover the files.Low-cost data archiving: It is possible to move data archives to certain levels of AWS S3 services like Glacier storage classes, which is one of the cheap and durable archiving solutions for compliance purposes; thus, data can be retained for a longer timeSecurity and Compliance: Amazon S3 provides multiple levels of security, including Data Access Security, Identity and Access Management (IAM) policies, Access Control Lists (ACLs), etc. It supports compliance features for HIPAA/HITECH, Data Protection Directive, FedRAMP, and others.
Concepts in Amazon S3
Buckets: S3 organizes data into containers called buckets. Each bucket has a globally unique name and serves as a logical container for objects.
You can see more about Buckets from here: Basics BucketObjects: Objects are the fundamental entities stored in S3. They consist of the data you want to store and associated metadata.
You can see more about Objects from here: Basics ObjectsKeys: Keys are unique identifiers for objects within a bucket. They represent the object’s path and can include prefixes and subdirectories to organize objects within a bucket.
You can see more about Keys from here: Basics KeysS3 Versioning: S3 supports versioning, which enables you to store multiple versions of an object. This feature helps in tracking changes and recovering from accidental deletions or modifications.
You can see more about S3 Versioning from here: S3 VersioningVersion ID: In Amazon S3, when versioning is enabled for a bucket, each object can have multiple versions. Each version of an object is assigned a unique identifier called a Version ID. The Version ID is a string that uniquely identifies a specific version of an object within a bucket.
You can see more about Version ID from here: Basics Version IDBucket policy: A bucket policy in Amazon S3 is a set of rules that define the permissions and access controls for a specific S3 bucket. It allows you to manage access to your S3 bucket at a more granular level than the permissions granted by IAM (Identity and Access Management) policies.
You can see more about Bucket policy from here: Bucket PoliciesS3 Access Points: S3 Access Points in Amazon S3 provide a way to easily manage access to your S3 buckets. Access points act as unique hostnames and entry points for applications to interact with specific buckets or prefixes within a bucket.
You can see more about S3 Access point from here: Basics Access PointsAccess control lists (ACLs): ACLs (Access Control Lists) in Amazon S3 are a legacy method of managing access control for objects within S3 buckets. While bucket policies and IAM policies are the recommended methods for access control in S3, ACLs can still be used for fine-grained control in specific scenarios.
You can see more about ACLs from here: S3_ACLsRegions: S3 is available in different geographic regions worldwide. When you create a bucket, you select the region where it will be stored. Each region operates independently and provides data durability and low latency within its region.
You can see more about Regions from here: Regions
NOTE: You can access Amazon S3 and its features only in the AWS Regions that are enabled for your account.
How does Amazon S3 Works?
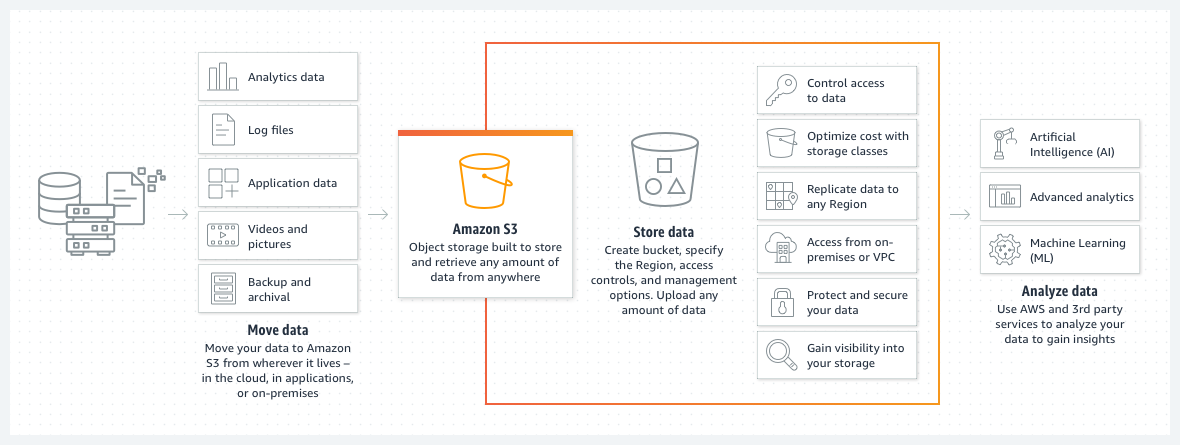
You create a bucket. A bucket is like a folder that holds your data.
You upload your data to the bucket. You can upload files of any size, and you can even upload folders and subfolders.
You can access your data from anywhere. You can use the Amazon S3 website, the AWS Command-Line Interface (CLI), or any other application that supports Amazon S3.
AWS S3 Storage Classes
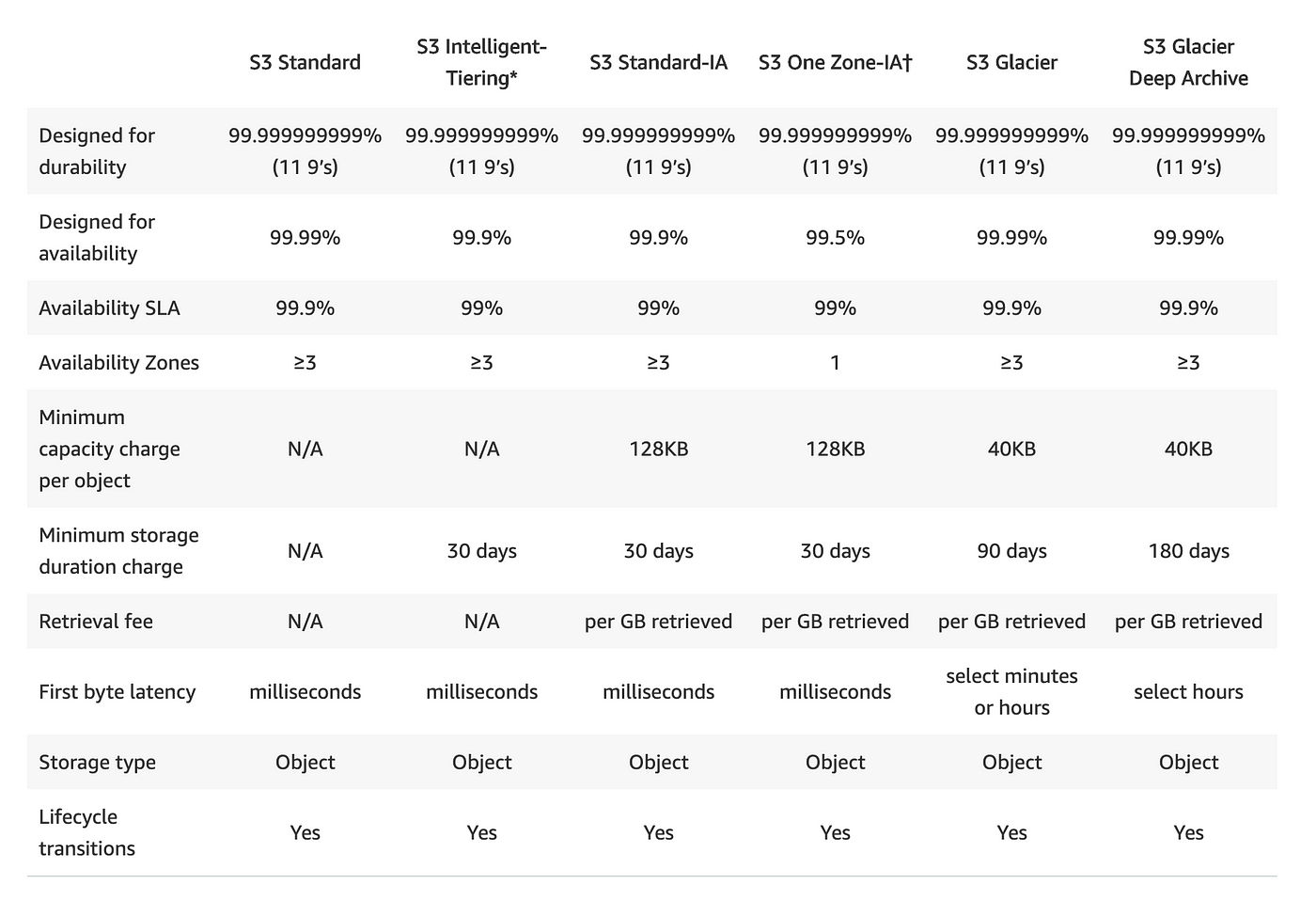
Amazon S3 offers seven storage classes, including: -
S3 Standard: It is the default and the most expensive storage, class. It supports frequently-accessed data that require low latency and high throughput. This tier is ideal for cloud migration processes to other classes, content distribution, dynamic websites, big data workloads, and applications.S3 Intelligent-Tiering: It supports data with either unknown or changing access needs. This tier provides four types of access, including Frequent Access, Archive, Infrequent Access (IA), and Deep Archive. The tier analyzes customer access patterns and then automatically moves data to the least expensive tier.S3 Standard-IA: It is good for backups, long-term storage, and disaster recovery-based use cases. It supports infrequently-access data that require quick access. This tier offers lower storage prices, ideal for long-term storage, backup, and data recovery (DR) scenarios.S3 One Zone-IA: It supports infrequently-access data that requires rapid access when needed. This tier does not offer high resilience and availability, which is why it is only suitable for data you can easily recreate, or is already saved in other locations.S3 Glacier: It supports primarily archival storage scenarios. This tier offers cost-effective storage for data that can suffer long retrieval times. It offers variable retrieval rates ranging between minutes and hours. Data must be stored for at least 90 days and can be restored within 1-5 minutes, with expedited retrieval.S3 Glacier Deep Archive: It supports data that requires access only once or twice per year. This tier offers the lowest storage S3 prices. Data must be stored for at least 180 days, and can be retrieved within 12 hours. There is a discount on bulk data retrieval, which takes up to 48 hours.S3 Outposts: It delivers object storage to your on-premises AWS Outposts environment to meet local data processing and data residency needs. Using the S3 APIs and features, S3 on Outposts makes it easy to store, secure, tag, retrieve, report on, and control access to the data on your Outpost. You can use S3 Outposts when your performance requirements call for data to be retained near on-site applications or to meet specific data residency stipulations.
Tasks
Task 1: Create a S3 bucket and access data using AWS-CLI.
In this task, we will:
-> First, Launch an EC2 instance using the AWS Management Console and connect to it using Secure Shell (SSH).
-> Second, Create an S3 bucket and upload a file to it using the AWS Management Console.
-> Lastly, Access the file from the EC2 instance using the AWS Command Line Interface (AWS CLI).
Let's begin with the steps👇
Step 1: Login to AWS Console and on search bar type "EC2".
Step 2: Launch an instance with the below details.
Name: S3-AWS-CLI
Number of instance: 1
AMI : Ubuntu
Instance type: t2-micro
Key-pair: Create or select a key-pair
Network Settings: Check the boxes “Allow HTTPS traffic from the Internet” & “Allow HTTP traffic from the Internet”
And leave the other options as it is.





Step 3: Click on "Launch Instance".

Step 4: Connect the instance to terminal using SSH Client. Perform the steps given in the below Screenshot.


Step 5: Now, Search S3 in the AWS Console.

Step 6: Click on S3. You will see the below page.

Step 7: Click on "Create Bucket". Give name of your bucket which must be a unique name and leave all the other options as default.




Step 8: Click on "Create Bucket". Your bucket got created successfully.

Step 9: Now, Let us upload a file to the bucket we created just now.
Step 10: Click on your bucket you just created. And in the objects section click on Upload.

Step 11: Click on Add Files and select the file you want to upload.

Step 12: File has been added as you can see below. Now click on "upload".


Step 13: Now, Access the file from the EC2 instance using the AWS CLI.
Here’s the link to Install AWS CLI and configure the CLI with credentials.
Step 14: To check the S3 buckets present use the below command.
aws s3 ls

Step 15: Let’s create a file in the instance and upload it to the S3 using CLI.
echo "This is for testing purposes" > sample.txt
cat sample.txt

Step 16: Now copy this file to our bucket.
aws s3 cp sample.txt s3://mys3bucket.21

Step 17: This can be verified in the AWS Console under S3.

Step 18: Let’s download a file from the console to your local using CLI.
aws s3 cp s3://mys3bucket.21/S3_bucket.png .

Step 19: Now, Let us sync the contents of the local folder with our bucket.
touch file{1..10}.txt
#aws s3 sync <local-folder> s3://bucket-name
aws s3 sync . s3://mys3bucket.21


Step 20: This sync can be verified in the console.

Step 21: To list the objects in an S3 bucket use the below command
aws s3 ls s3://bucket-name
aws s3 ls s3://mys3bucket.21

Step 22: To delete an object from an S3 bucket use the below command
aws s3 rm s3://bucket-name/file.txt
aws s3 rm s3://mys3bucket.21/file1.txt

Step 23: To create a new bucket use the below command
aws s3 mb s3://bucket-name
aws s3 ls



Step 24: To delete a bucket from S3 use the below command
aws s3 rb s3://bucket-name


Task 2: Create a snapshot of the EC2 instance and download a file from the S3 bucket using the AWS CLI.
In this task, we have to:
-> First, Create a snapshot of the EC2 instance and use it to launch a new EC2 instance.
-> Second, Download a file from the S3 bucket using the AWS CLI.
-> Lastly, Verify that the contents of the file are the same on both EC2 instances.
NOTE: In Amazon EC2, you can create a snapshot of an EBS (Elastic Block Store) volume to create a point-in-time copy of the data stored on the volume. This snapshot can be used to back up data, migrate volumes between regions, or create new volumes from the snapshot.
Let's begin with the steps👇
Step 1: Go to the instances page in the AWS Console.
Step 2: On the left side, you will see "Elastic Block Store".

Step 3: Click on Snapshots under EBS. You will see the below page.

Step 4: Click on Create Snapshot. You will see the below page.

Step 5: Select Instances under Resource type. And select instance id.

Step 6: Click on "Create Snapshot".

Step 7: Let us use this Snapshot to launch a new EC2 instance.
Step 8: Select the Snapshot > Click on Actions > Select Create image from the snapshot.

Step 9: Give the below details for creating image.
Name: S3-image
Description: image for snapshot
And leave all the details as it is


Step 10: Click on "Create image".

Step 11: In the AMI section on the left side, you can observe that the AMI is created.

Step 12: Select the Image > Click on Launch Instance from AMI using the below details.
Name: S3-AWS-CLI-Snapshot
Number of instance: 1
AMI: It will be your image
Instance type: t2-micro
Key-pair: Create or select a key-pair
Network Settings: Check the boxes “Allow HTTPS traffic from the Internet” & “Allow HTTP traffic from the Internet”
And leave the other options as it is.




Step 13: Click on "Launch Instance".


Step 14: Connect the Snapshot instance to terminal using SSH Client.
I was getting the below error.

So, I tried this and get connected to the instance. Instead of root just used ubuntu.

Step 15: We can access the bucket list which we have created via "S3-AWS-CLI" instance and can download the content of bucket.


So, You can see the contents of S3-AWS-CLI and S3-AWS-CLI_Snapshot instances are same.
Conclusion
In Conclusion, Amazon S3 (Simple Storage Service) is a scalable and secure object storage service provided by Amazon Web Services (AWS). It offers a reliable and cost-effective solution for storing and retrieving any amount of data at any time. S3 provides high durability by replicating data across multiple facilities and offers various storage classes to cater to different performance, access, and cost requirements.
The storage classes in Amazon S3 include Standard, Intelligent-Tiering, Standard-IA (Infrequent Access), One Zone-IA, Glacier, and Glacier Deep Archive. Each class is designed to optimize costs and performance based on the access patterns and retrieval requirements of the stored data.
In this blog, we have look into how to create a S3 bucket and access data using AWS-CLI and how to create a snapshot of the EC2 instance and download a file from the S3 bucket using the AWS CLI.
Hope you find it helpful🤞 So I encourage you to try this on your own and let me know in the comment section👇 about your learning experience.✨
*👆The information presented above is based on my interpretation. Suggestions are always welcome.*😊
~Smriti Sharma✌




